Xception: Deep Learning with Depthwise Separable Convolutions
写在前面
本篇是由谷歌AI研究员、Keras作者发表在CVPR-2017上的一篇论文,文章基于Inception结构进行了改进,在不增大模型体积的前提下,有限提升了在ImageNet上的性能,较大提升了在谷歌内部数据集JFT上的性能
主要思想
文章由Inception V3结构出发,Inception的初衷是:特征的提取可以通过1x1卷积,3x3卷积,5x5卷积(可以用两个叠加的3x3卷积代替),pooling等,到底哪种才是最好的特征提取方式呢,Inception决定让模型自己学习这些层的组合方式,所以并行的分别做了这几种特征提取,最后concat,如下图所示:
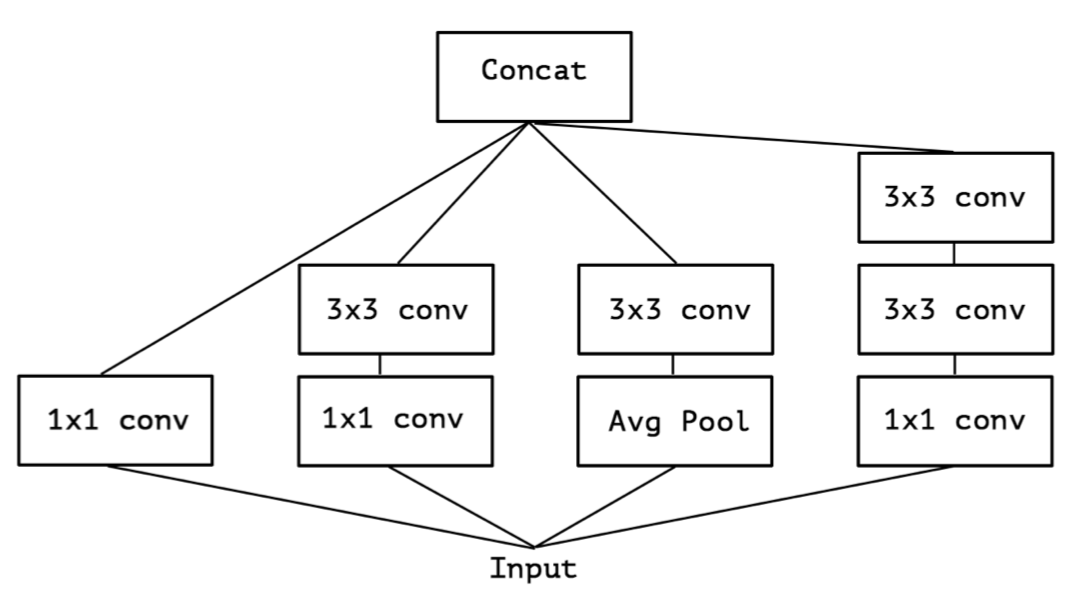
对这种结构做一点延伸,先对输入做统一的1x1卷积操作,然后把输出的所有channel分别做3x3卷积,类似于depthwise conv但又有区别,作者把这种结构称为extreme inception,Xception:
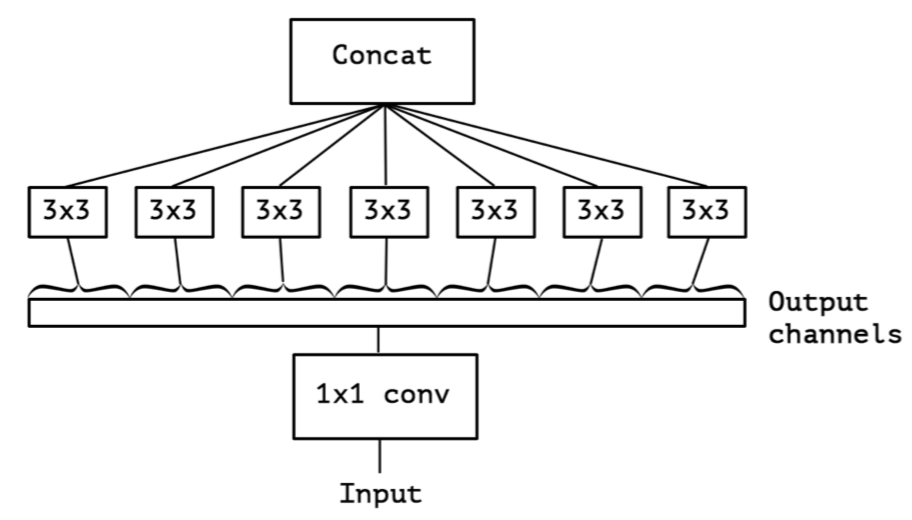
作者详细说明了Xception结构和Depthwise conv的区别:
- 卷积的顺序不同:Xception是先用1x1卷积再做3x3卷积,而depthwise conv则相反
- 非线性层的使用不同:Xception在两个卷积层都用了RELU,而depthwise conv则在第一个卷积之后不再用RELU
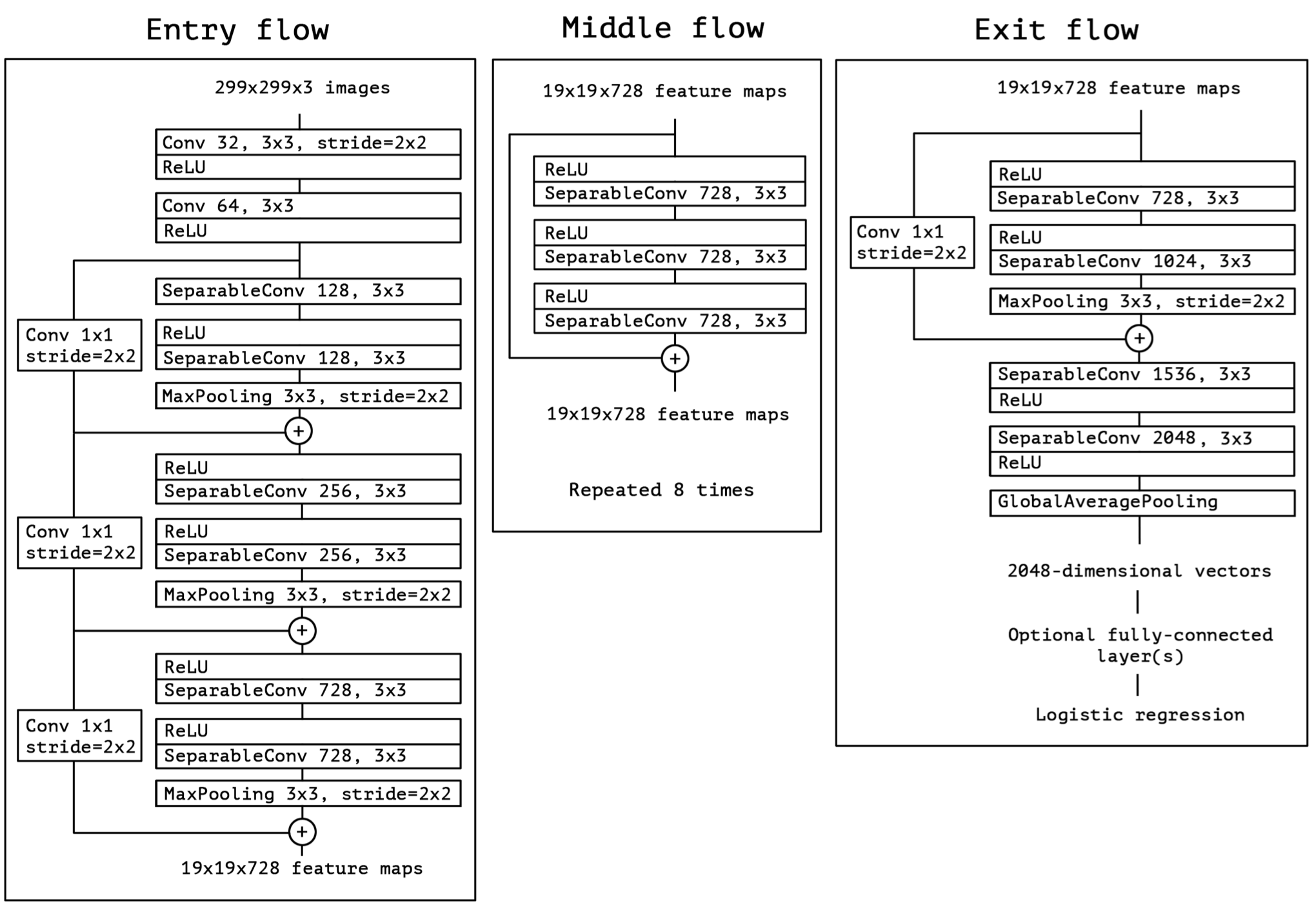
网络结构
Xception网络基于一系列Xception unit组成,并且引入了ResNet的残差连接:”The Xception architecture has 36 convolutional layers forming the feature extraction base of the network…The 36 convolutional layers are structured into 14 modules, all of which have linear residual connections around them, except for the first and last modules.”
开源代码
原作者在github上开源了本文的代码:TensorFlow-Xception
参考文献
-
Previous
轻量级卷积神经网络(三):ShuffleNet V1 & V2 -
Next
Aggregated Residual Transformations for Deep Neural Networks