SQUEEZE NET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
写在前面
SqueezeNet由伯克利和斯坦福的科研人员合作发表于ICLR-2017,作者明确说了SqueezeNet不是一种模型压缩技术,而是”design strategies for CNN architectures with few parameters”,是一种新的模型结构
文章开篇就提到了轻量级网络的3个优势:
- 更适合分布式训练:参数更少,训练过程中涉及到的参数更新的通信量就更小
- 迁移到端上开销更小:小的模型更适合迁移到诸如自动驾驶之类的客户端上
- 更适合FPGA等嵌入式设备:嵌入式设备往往资源有限,轻量级网络可以很好胜任
主要思想
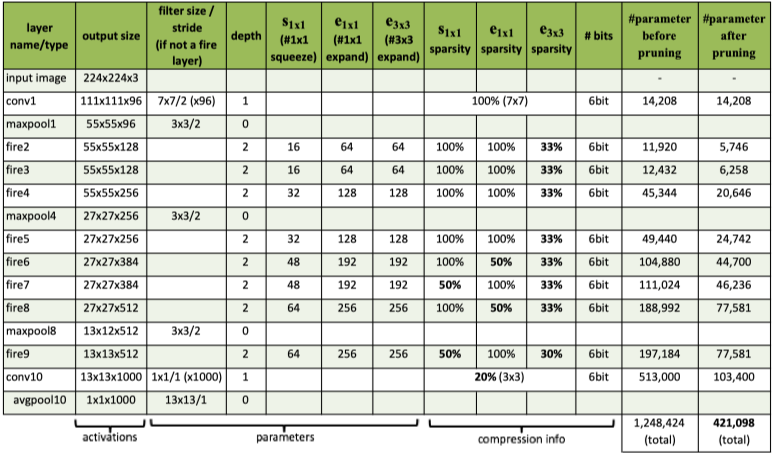
本文介绍了一种fire模块,SqueezeNet主要是由fire模块构成的,并进一步用了深度压缩(Deep Compression)技术来削减模型体积
-
Fire Module
“A Fire module is comprised of: a squeeze convolution layer (which has only 1x1 filters), feeding into an expand layer that has a mix of 1x1 and 3x3 convolution filters”
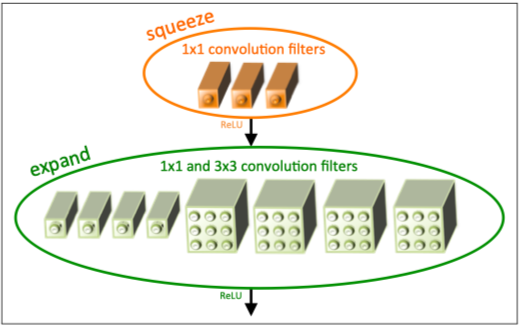
可以理解为,先用1x1卷积做squeeze,压缩特征图的channel数,然后再用1x1卷积和3x3卷积分别做expand,增加channel数,并在最后把结果concat起来;总体来说减少了3x3卷积的数量,提高了1x1卷积在整个模型中占的比重
-
Deep Compresion
本文在SqueezeNet网络的基础上还采用了韩松的深度压缩技术,用6/8-bits来量化模型,进一步压缩了模型体积,取得了相对AlexNet 510x的体积压缩(240MB-0.47MB),同时精度不掉的效果
模型结构
“SqueezeNet begins with a standalone convolution layer (conv1), followed by 8 Fire modules (fire2-9), ending with a final conv layer (conv10).We gradually increase the number of filters per fire module from the beginning to the end of the network. SqueezeNet performs max-pooling with a stride of 2 after layers conv1, fire4, fire8, and conv10;”
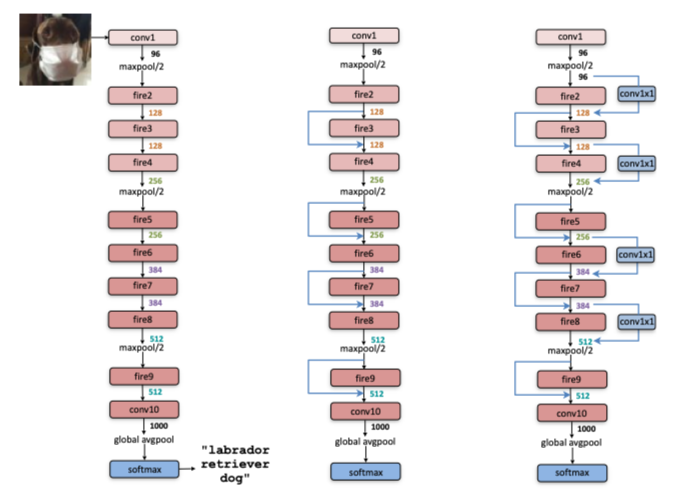
文章介绍了三种SqueezeNet结构,并且经过实验,中间的带有简单shortcut的结构是最优的
现代的CNN普遍用global average pooling代替了FC
开源代码
作者开源了Caffe代码,并收录了一些其他框架的开源实现供读者参考:SqueezeNet