Deep Residual Learning for Image Recognition 论文阅读简记
写在前面
本篇介绍一下Computer Vision领域乃至整个Deep Learning领域的mile stone:ResNet. ResNet在2015年的ImageNet和Coco比赛上都获得了冠军.
ResNet参数量相比VGG有所降低,而且性能更好,这种结构也被证明可以加速网络的训练,也有很好的推广性,甚至可以直接用到InceptionNet的网络中.
主要思想
ResNet沿袭了Highway Network的思想,在网络中增加了直连通道,允许保留之前网络层一定比例的输出,原始输入信息直接传到后面的层中. 这样的结构相当于网络在学习层之间的残差,实验证明,这样的残差网络更容易优化,因为没有了退化问题,我们可以单纯的提升网络深度来提高性能。
什么是深层网络的退化问题?
人们发现更深的网络一般可以有更好的性能,所以尝试简单的增加深度,但是在这个过程中发现了梯度消失和梯度爆炸(gradient vanising/exploding)的问题。为了解决这个问题,人们又尝试了用输入归一化和中间层归一化(BatchNorm)的方法。这确实解决了梯度传播训练的问题,但是人们又发现:在网络层数深度增加时,性能却反而下降了。这个问题甚至不能解释为overfitting,因为训练集上的表现也存在退化现象(overfitting的话,起码在训练集上会变得更好).
这个退化问题说明了传统的深层网络并不能被很好的优化,需要引入一种新的结构。
如何解决退化问题?
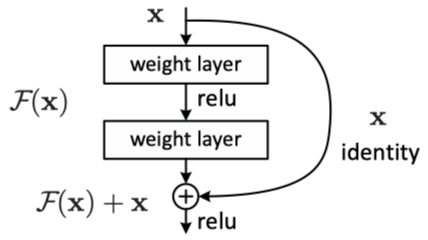
作者引入了一个恒等映射\(x\),整个网络的输出可以表示为\(H(x)=F(x)+x\),所以图中这个结构就变成了学习\(F(x)=H(x)-x\)这部分残差. 拟合这部分的残差难度相对而言更容易。拟合残差的好处下面这段话解释的很到位:
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…
网络结构
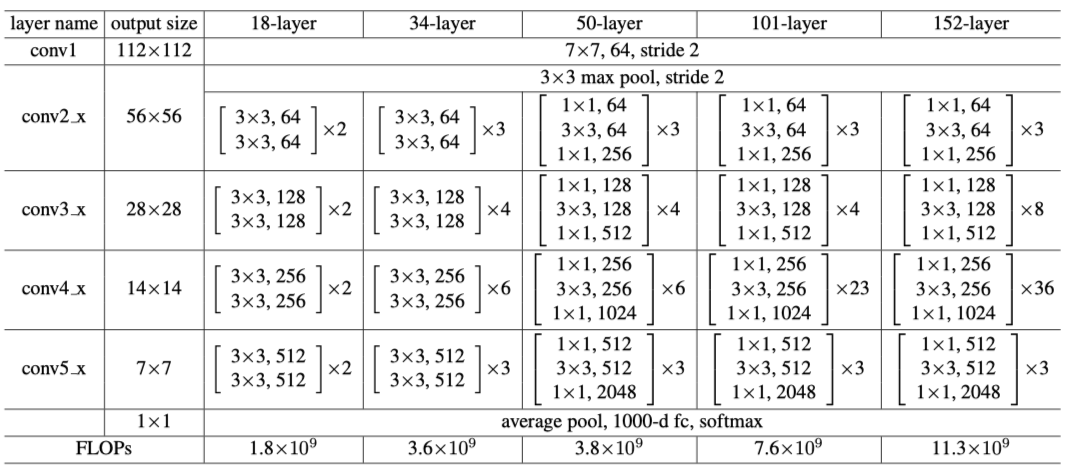
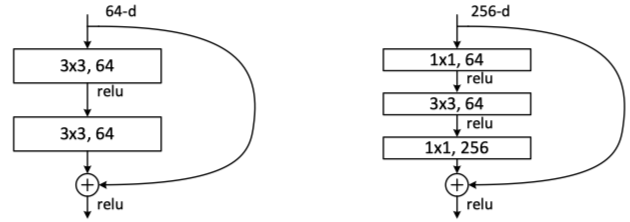
ResNet首先引入了bottleneck结构,如上图右边结构,先通过1x1降维减少参数量,再做3x3的卷积提特征,最后再用1x1的卷积升维来完成维度的匹配(256-256),这样的做法可以很好的减少网络的参数量和计算时间。
开源代码
作者没有开源代码,可以参考github上其他高star的代码resnet-in-tensorflow