Rethinking ImageNet Pre-training 论文阅读简记
写在前面
本篇主要介绍了对在CV领域尤其是Object Detection方向经常使用的ImageNet pre-training这种方法的重新思考,并且证明了在一些情况下直接Train From Scratch(TOS)也可以取得与pretrain方法相当的结果, 甚至在一些位置敏感的任务中(Object Detection)可以取得更好的效果。
主要思想
近年来,一种使用Pre-train的范式越来越被广泛的采用,基本方法是使用大量的数据(例如ImageNet)进行预训练,然后针对任务使用少量数据进行fine-tune。这种pre-train的方法已经在多个任务上取得了state-of-art的结果。
然而本文的实验结果发现,使用COCO数据从头(train from scratch)训练可以取得与预训练方法相当的结果,这在object detection和instance segmentation任务上都得到了验证。
所以这篇文章主要是研究同一种模型使用/不使用ImageNet预训练的性能表现差异。网络结构的变更并不是本工作关心的问题。针对本文的工作点,有两个问题值得关注:1.归一化,2.训练的轮数
1.Normalization
Batch Normalization(BN)是一种人民群众喜闻乐见的训练模型的方法。在Object Detection任务里,通常是用一些高解析度的图片进行训练,不同于Image Classification(ImageNet: 224x224)。因为内存的限制,目标检测任务的batch size都很小, 然而batch size的减小对BN精度有很大影响。当使用pre-train方法时,这个问题可以避免:因为fine-tune过程可以使用pre-train过程的BN数据作为固定参数(这点在ResNet论文中已经说明过);但是如果TOS,这个问题将不可忽略。
这里作者也提到了两种方法减轻小batch size的不良影响:
1).Group Normalization(GN), 组归一化,凯明大神近期的论文,区别于BN,GN在channel维度上做归一化
2).Synchronized Batch Normalization (SyncBN),使用多卡增大batch size,做BN同步来解决这个问题
2.Convergence
从头训练当然是不会和fine-tune一样快的,所以如果使用TOS,训练的Epoch需要增多。下图表明,经过足够多的iterations,TOS是可以取得和pretrain一样好的结果的,论文在多个模型上都验证了这个结论。
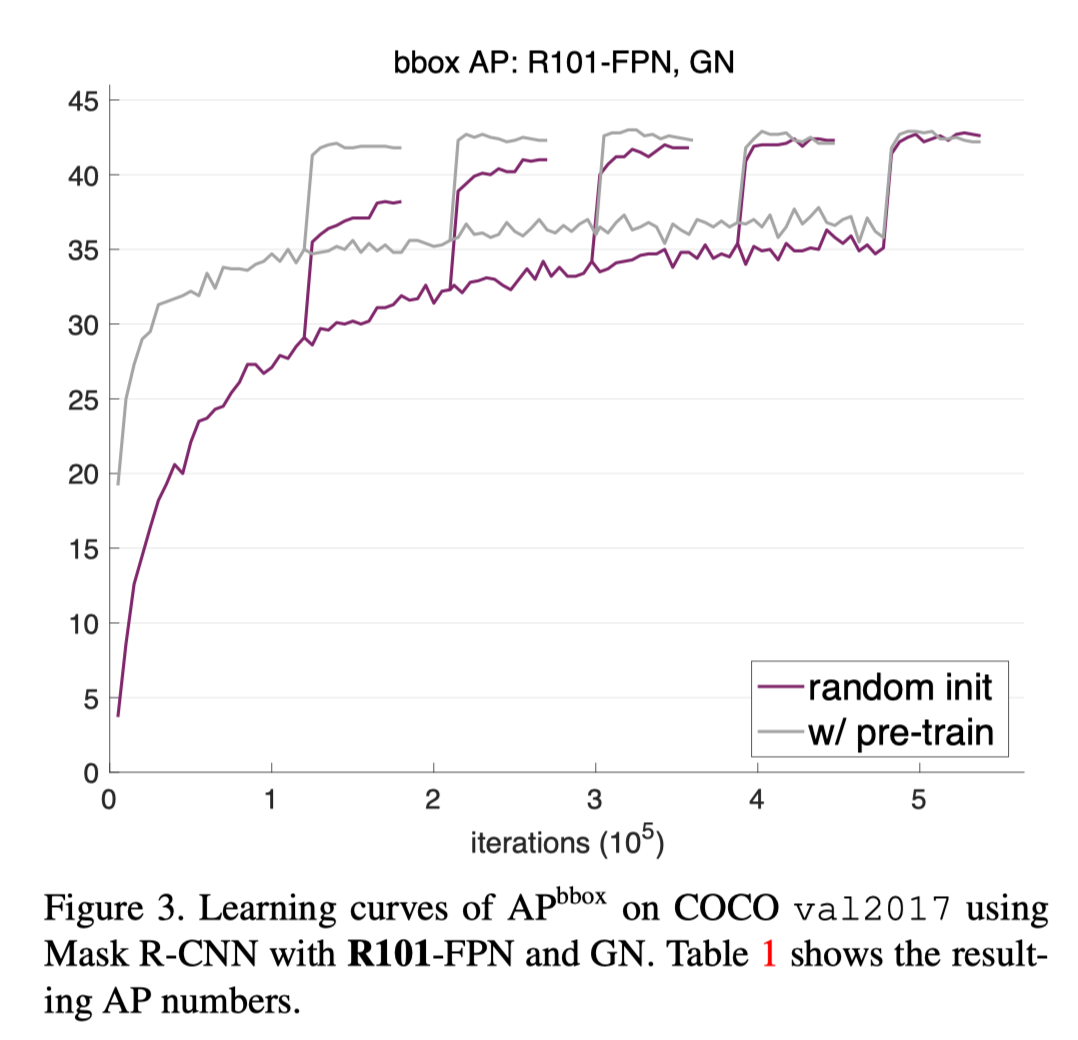
最终结论
- 不做网络结构的改动,training from scratch也是可能的
- Training from scratch为了达到足够好的收敛结果需要更多轮迭代
- Training from scratch可以取得与ImageNet pre-training一样好的结果
- ImageNet pre-training确实加快了收敛速度
- ImageNet pre-training其实并没有想象中防止过拟合的效果(除非数据集非常小)
- ImageNet pre-training在一些位置敏感的任务上的表现欠佳