Sequence models & Attention mechanism
Various sequence to sequence architectures
Seq2seq model
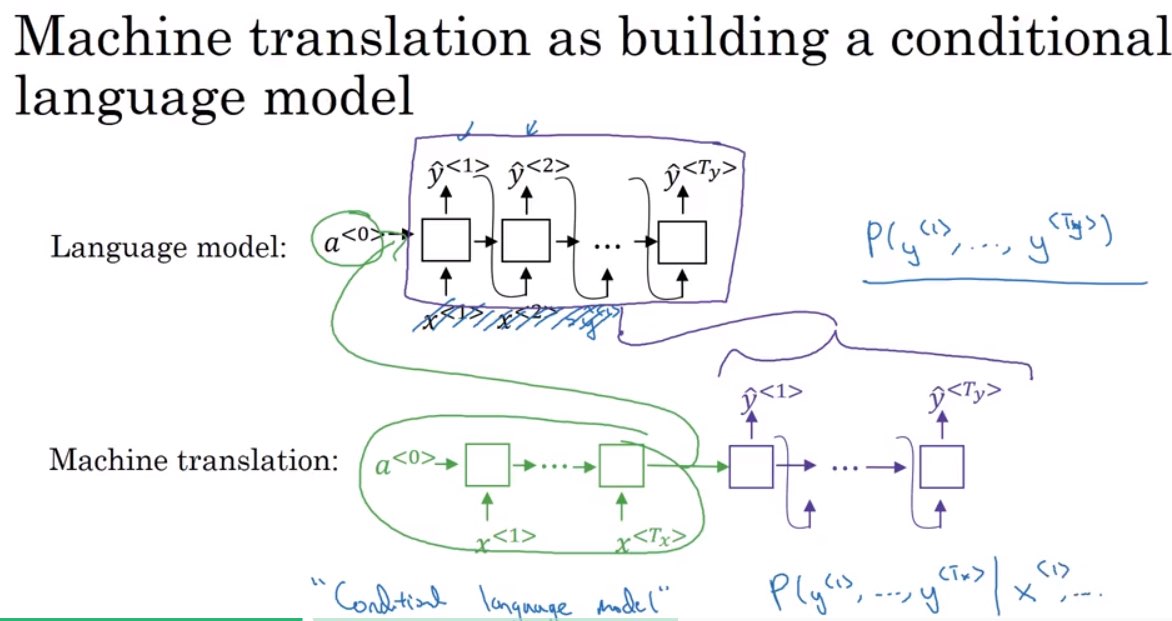
机器翻译模型常常是encoder-decoder结构,也可以称为条件语言模型
- 通常是经过编码器(绿色部分)把一句话转化为一个向量,再经过解码器输入这个向量并用beam search算法计算出概率最大的翻译
- BEAM SEARCH是通过一个B值来同时保留几种有可能的翻译结果,beam search目标是最大化以下的结果
Refinements to Beam Search
传统beam search 求解的问题是:
\[arg\ max\prod _{t=1}^{T_y}P(y^{<t>}|x,y^{<1>},...,y^{<t-1>})\]这样带来一个问题,如果概率值很小,连乘后将不能被计算机有效的计算和存储,所以一种改进是用log函数将连乘问题转换为连加问题
\[arg\ max\sum_{t=1}^{T_y}logP(y^{}|x,y^{<1>},...,y^{})\]Beam with B?
large B: better result, slower
small B: worse result, faster